|
Hello! I am Luca, a recent PhD graduate from the Joint PhD Program in Statistics and Machine Learning at Carnegie Mellon University, where I was fortunate to be advised by Ann B. Lee and co-mentored by Barnabás Póczos. During my PhD, I focused on robust uncertainty quantification in likelihood-free settings: I developed methods with sound statistical guarantees leveraging modern machine learning (e.g., deep generative models) to quantify the uncertainty on parameters that govern complex physical processes. I have also been working on foundation models, probabilistic forecasting and optimization during various internships, and I am keen on learning more about these topics too. At CMU, I am part of the Statistical Methods for the Physical Sciences (STAMPS) group. My research has been supported by the National Science Foundation (grant #2020295) and by the CMU 2024 Presidential Fellowship for the Statistics Department. Before joining CMU, I obtained an M.Sc. in Data Science (Statistics) at Bocconi University in Milan (Italy), where I was advised by Igor Pruenster and Antonio Lijoi. Email: CMU - Gmail | CV | Scholar | Github: Personal - Group | LinkedIn |

|
|
|
|
|

|
Under Review, 2025 [paper ] What’s the optimal way to distinguish between two theories? For decades, the lore has been that this problem was solved: the Neyman-Pearson lemma tells us to calculate the likelihood ratio. But the lore is missing a detail. The LR is only optimal for “simple” theories without parameters. If your theory has a parameter (composite hypothesis tests), e.g. masses or couplings, then the NP lemma doesn’t guarantee optimality! And almost every theory has a parameter. The LR is still good, but it’s not necessarily optimal for all values of your parameter. Using the LR implicitly chooses some spread of statistical power. Is it the spread we want? What if we could choose where to have greatest sensitivity? In this paper, we introduce the “focused test statistic”, which can tune its focus to a region of interest. Confidence intervals from the FTS are narrower than those from the LR! What if you focus in the wrong place? Is this just bayesian priors? Frequentist intervals guarantee coverage, unlike bayesian approaches, regardless of focus. So it’s not wrong, just not optimal. Isn’t it computationally expensive to do frequentist statistics? Yes, but we also introduce an ML technique, quantile regression, for fast frequentist intervals, even in high dimensions. |
 
|
[ pdf: low-res / high-res (Kilthub) ] In this dissertation, we introduce several novel techniques to leverage regression, classification, and generative models to construct confidence sets with strong statistical guarantees. The methods we develop allow one to derive confidence sets that are simultaneously (1) valid across the entire parameter space and in finite samples, (2) robust to prior probability shifts, (3) as precise as possible when prior knowledge aligns with the target distribution, and (4) computationally efficient. |

|
ICML, 2025 [ paper ] We develop a wavelet-based tokenizer that allows language models to learn complex representations directly in the space of time-localized frequencies and achieve superior forecasting accuracy. By decomposing coarse and fine structures in the inputs, wavelets provide an eloquent and compact language for time series that simplifies learning. |

|
ICML, 2024 [ paper / code ] We propose a new method for robust uncertainty quantification that casts classification as a hypothesis testing problem under nuisance parameters. The key idea is to estimate the classifier’s ROC across the entire nuisance parameter space, which allows us to devise cutoffs that are invariant under generalized label shifts. Our method effectively endows a pre-trained classifier with domain adaptation capabilities and returns valid prediction sets while maintaining high power. |
|
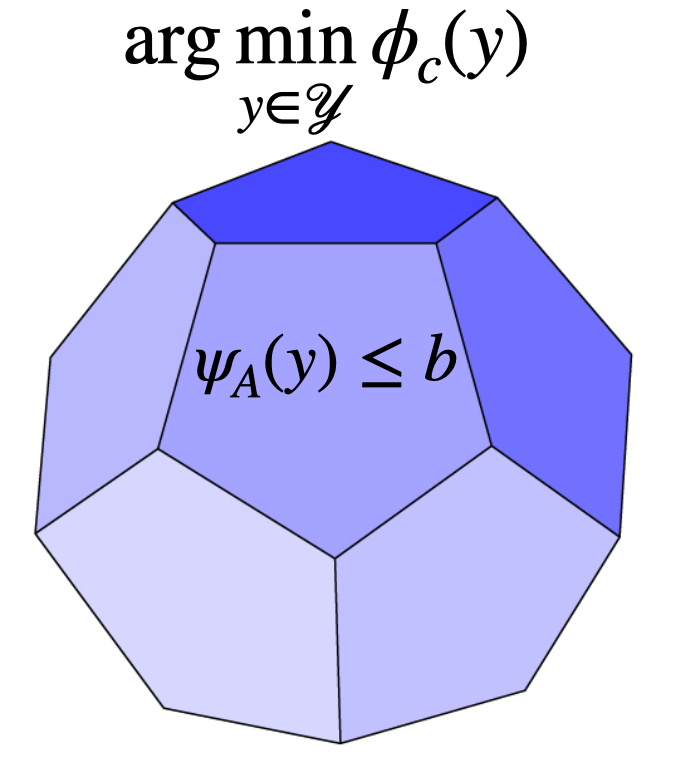
In preparation, 2023 We developed theory and methodology to embed arbitrary mixed-integer programs as differentiable blocks of deep learning pipelines via stochastic perturbations of the optimization inputs. We also proposed to exploit inluence functions to do sensitivity analysis on the combinatorial solvers and drive perturbations in the optimal direction. |
|
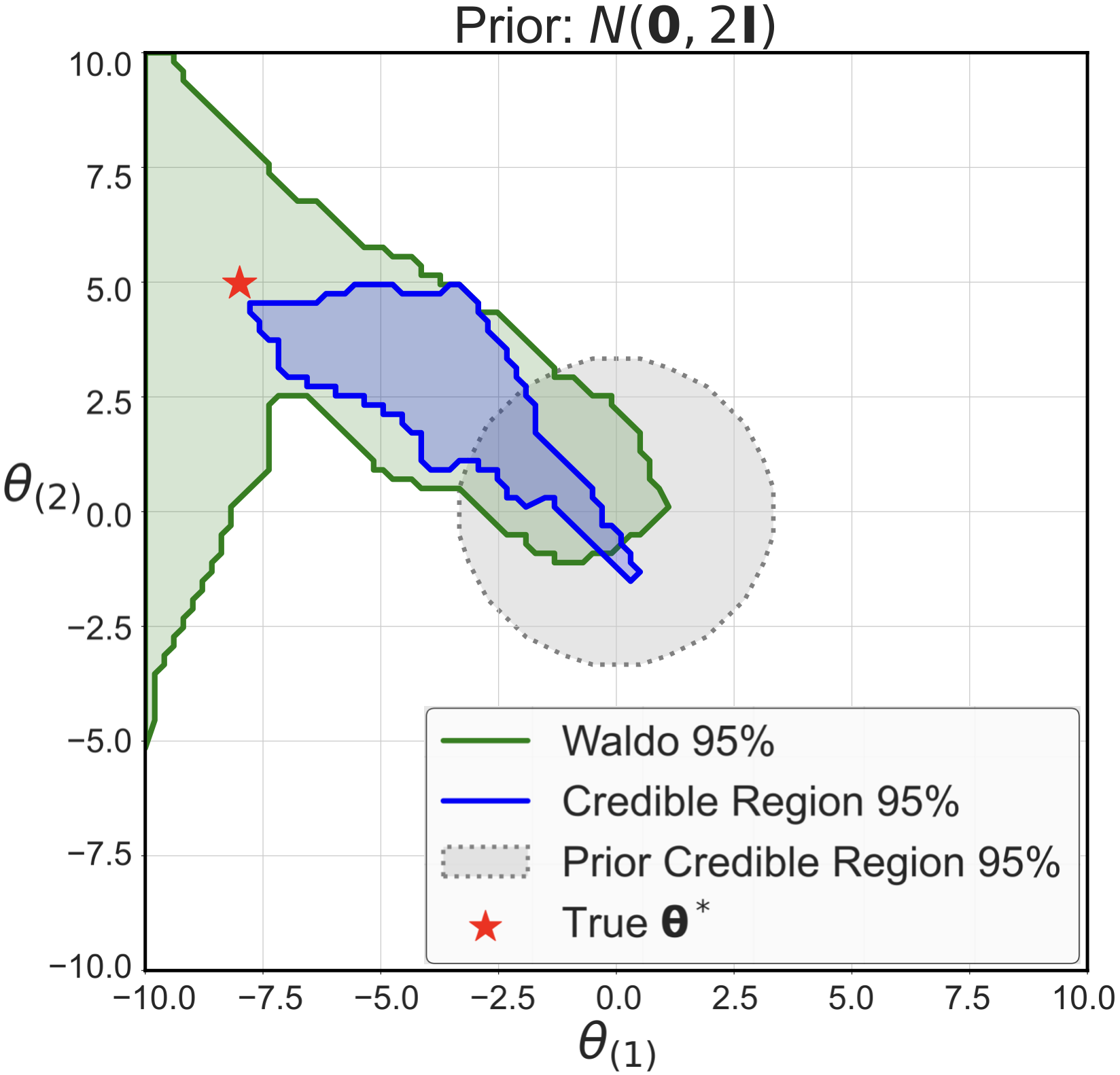
AISTATS, 2023 Winner of the 2023 American Statistical Association SPES Student Paper Competition [ paper / code / docs ] WALDO allows to exploit arbitrary prediction algorithms and posterior estimators to construct reliable confidence sets for parameters of interest in simulation-based inference, i.e. when the likelihood is intractable but we can sample from it. Confidence sets from WALDO are guaranteed to be valid at the correct coverage level without being overly conservative. In addition, one can still exploit prior knowledge to achieve tighter constraints. |
|
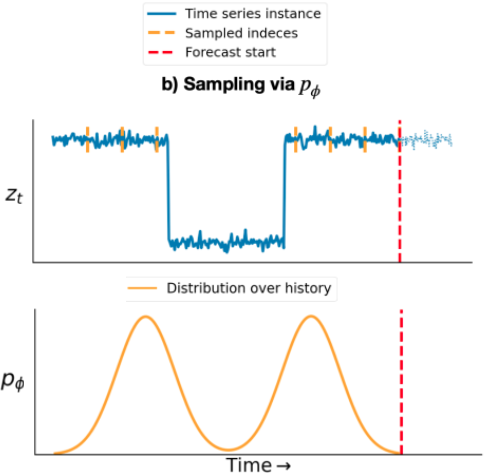
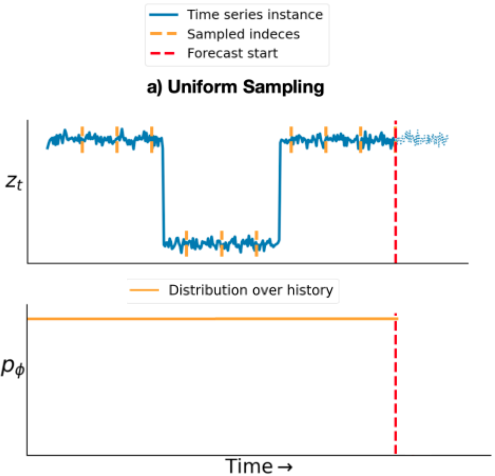
NeurIPS Distribution Shifts Workshop (DistShift), 2022 [ paper ] We present an adaptive sampling strategy that selects the part of the time series history that is relevant for forecasting. We achieve this by learning a discrete distribution over relevant time steps by Bayesian optimization. We instantiate this idea with a two-step method that is pre-trained with uniform sampling and then training a lightweight adaptive architecture with adaptive sampling. |
|
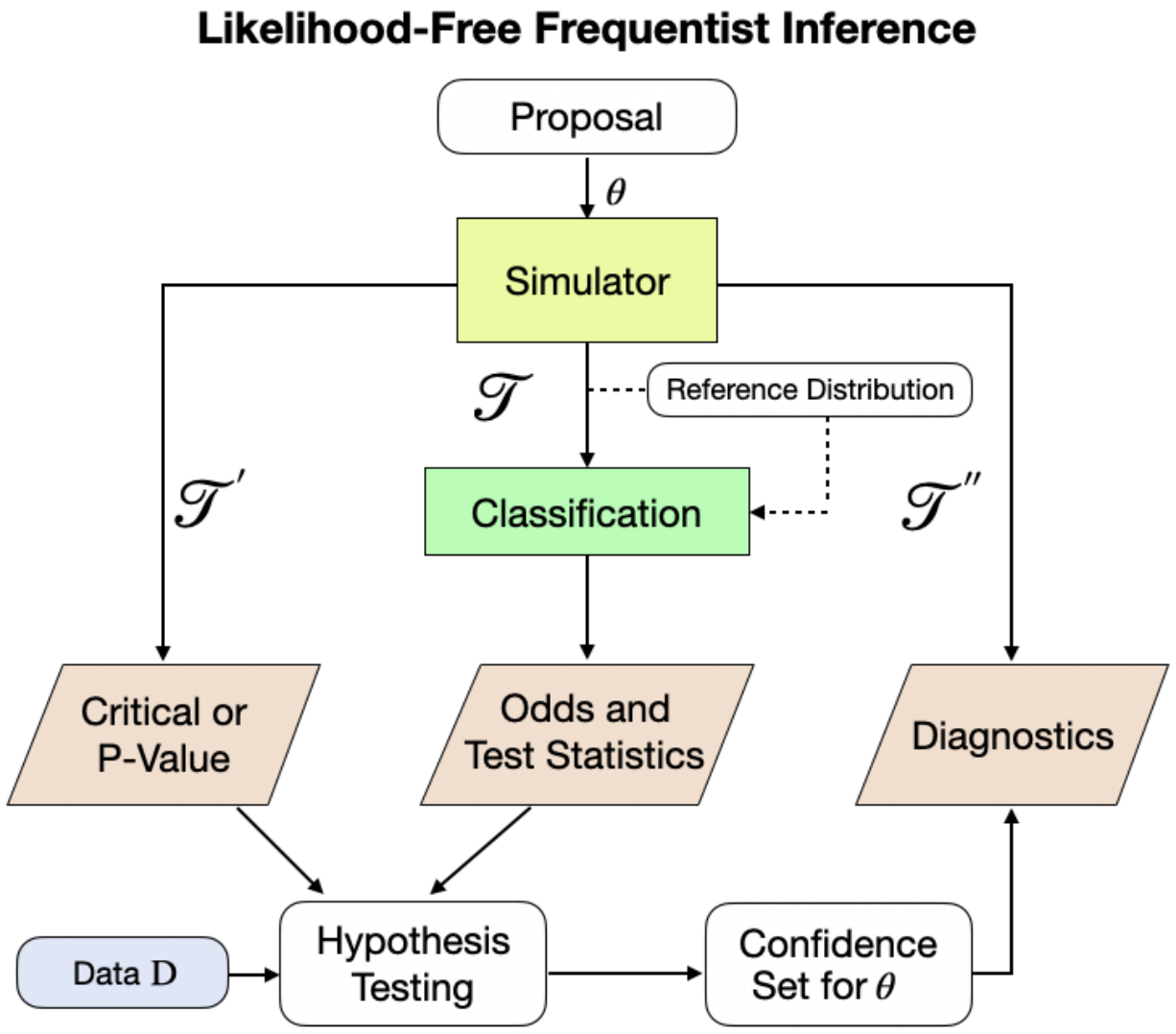
Electronic Journal of Statistics [ paper / code / docs / supplementary material ], *equal contribution In this work, we propose a unified and modular inference framework that bridges classical statistics and modern machine learning in SBI/LFI providing (i) a practical approach to the Neyman construction of confidence sets with frequentist finite-sample coverage for any value of the unknown parameters; and (ii) interpretable diagnostics that estimate the empirical coverage across the entire parameter space. |
|
|

|
Machine Learning Scientist Intern Manager: Danielle Robinson, Mentors: Ansari A.F., Han B., Zhang X., Rangapuram S. June-August 2024, Santa Clara (California) I worked on developing new Foundation Models for time series forecasting, specifically with an eye on using tokenizers based on wavelets. |
|
|
Machine Learning Scientist Intern Manager: Lorenzo Stella, Mentor: Syama Sundar Rangapuram June-August 2023, Berlin (Germany) Developed theory and methodology to embed arbitrary mixed-integer programs as differentiable blocks of deep learning pipelines via stochastic perturbations of the optimization inputs. Proposed to exploit inluence functions to do sensitivity analysis on the combinatorial solvers and drive perturbations in the optimal direction. |
|
|
Machine Learning Scientist Intern Manager: Michael Bohlke-Schneider, Mentor: Syama Sundar Rangapuram June-August 2022, Berlin (Germany) Built a time series forecasting method that is robust under distribution shifts. I proposed a novel adaptive sampling approach and delivered an implementation that (i) avoids noisy data regions, (ii) focuses on relevant shifted region in the past, and (iii) has also promising first results with real-world datasets with known distribution shifts. |

|
Quantitative Analyst Intern Manager: Joo Chew Ang July-September 2019, London (UK) Designed and developed a new research platform that allows to inspect the downstream effect of any modification in a suite of equity risk models. This platform streamlined the research process by reducing time between idea generation and implementation. I also worked with software engineers to refine compliance of production code with quantitative models' logic. |

|
Data Scientist Intern Mentors: Carlo Baldassi, Carlo Lucibello March-May 2019, Milan (Italy) Exploited various statistical models to improve real-time detection of damaged integrated circuits produced in a semiconductor plant in southern Italy. |
|
|